문서는 있는데, 찾기가 어렵습니다. 키워드를 정확히 알아야 하고, 결국 사람한테 물어보게 됩니다.
기록은 남기는데, 이어서 보기가 어렵습니다. 관련 이슈끼리 맥락을 연결해서 한눈에 보고 싶은데 안 됩니다.
협업하는 사람들의 문서를 연결해서 하나의 지식으로 볼 수 있는 방법이 없을까?
2021
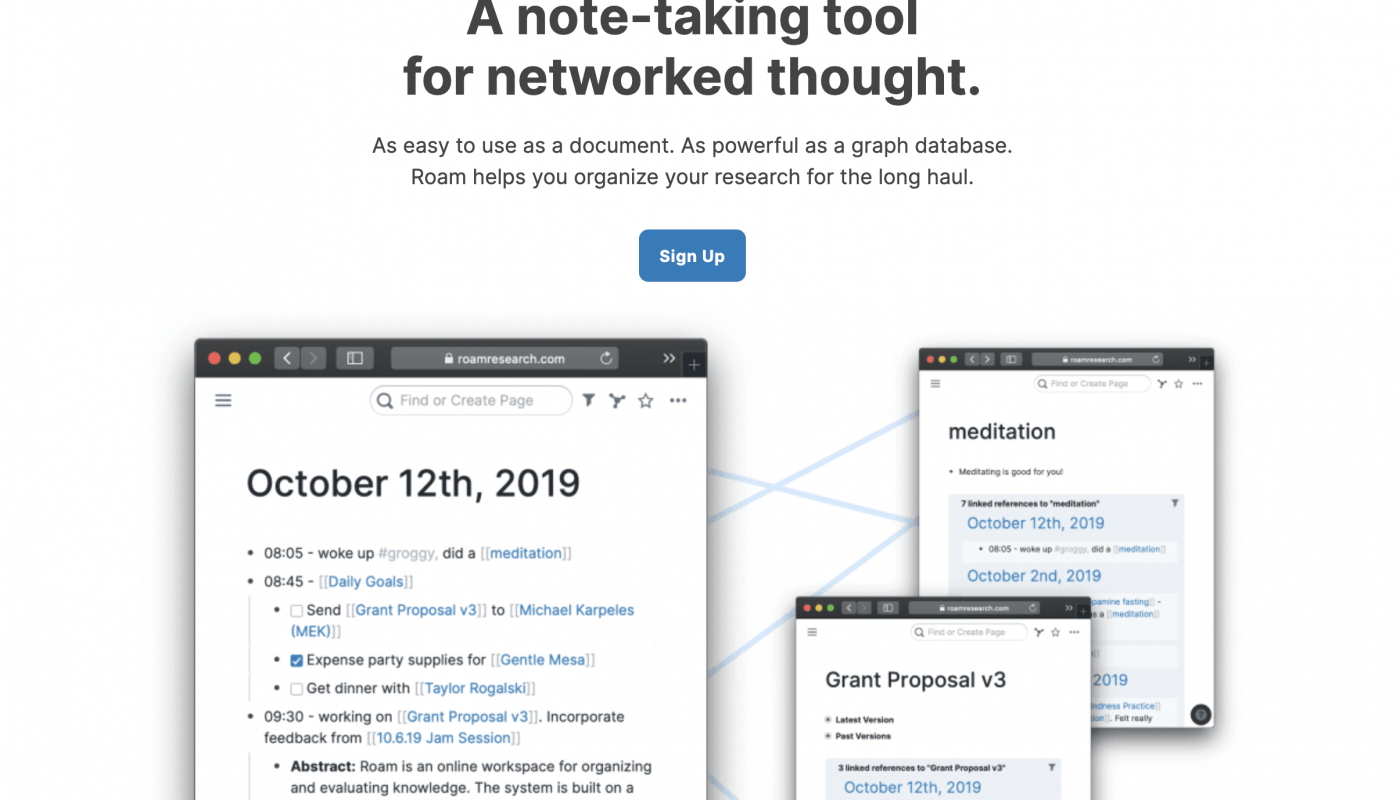
Roam Research와 Obsidian을 접함. 거의 완벽한 도구였지만, 진입장벽이 높고 관리 리소스가 많이 필요했음. 포기.
"A note-taking tool for networked thought"
팀에 공유하던 시절
2026
이번엔 달랐습니다. 처음부터 배울 필요가 없고, 관리도 Claude가 해줍니다.
Obsidian을 Claude의 뇌로 사용하자.
로컬 파일 — 전부 .md로 내 컴퓨터에 저장. 작업은 로컬에서, 공유는 Git으로.
위키링크 — [[문서명]]으로 문서 간 연결. Graph View로 시각화.
태그 — WORK.md에서 #상현#은별로 담당자, #고도화#루틴으로 분류. 검색·필터가 바로 됨.
Claude 호환 — 같은 폴더에서 검색·읽기·쓰기. 별도 연동 없음.
무료.
실제 vault의 Graph View — 문서끼리 연결된 구조
읽고, 쓰고, 쌓인다
1. 기준을 마크다운으로 정리 SQL 규칙, 기관별 기준, 과거 실수를 파일로 남겨둠.
2. Claude가 읽고 작업 CLAUDE.md는 세션 시작 시 자동 로드. docs·sql은 작업 중 Claude가 직접 검색해서 읽음.
3. 새로 알게 된 기준을 다시 저장 → 반복 다음 세션은 이번에 쌓인 지식까지 포함해서 시작됨.
CLAUDE.md 안에 실제로 뭐가 있나
우리 팀 CLAUDE.md는 이런 것들이 적혀있음:
· SQL 키워드 소문자, where true로 시작, 조인 alias는 t1·t2·t3
· KRW 금액은 amount / 1e4, any_value() 사용 금지
· 마트 컬럼명: 기간 > 집계함수 > 대상명사 > 속성 순서
· prod 테이블 조회 전 반드시 사람에게 확인
· 작업 완료 후 docs에 기준 문서 남기기
처음엔 10줄이었는데 지금은 200줄. 팀이 틀렸던 것, 반복했던 것이 전부 규칙이 됨. 이걸 매 세션 자동으로 읽으니까, 누가 Claude를 써도 같은 기준에서 출발.
이 문서들을 처음부터 앉아서 작성한 게 아님. CLAUDE.md만 직접 작성했고, Memory는 Claude가 알아서 저장. 62개 문서 + 30개 Memory는 수개월간 일하면서 자연히 쌓인 것.
CLAUDE.md — 팀 규칙서
Memory — 실수 교훈, 도메인 지식
WORK.md — Jira를 대체한 상태판
Jira에선 이슈 323건 중 본문이 있는 건 92건(28%). 나머지는 제목만 있는 빈 티켓.
WORK.md는 체크박스 한 줄에 담당자, 시작 주차, 기한, 태그, 기준 문서 링크가 다 붙어있음:
저희는 관리할 게 적을수록 본업에 집중할 수 있다고 생각해서, 가능한 한 단순하게 운영하고 있습니다.
필요한 정보는 레포를 clone해서 로컬에 둔다.
dbt 모델이 필요하면 dbt-metric 레포를 clone. Airflow DAG 구조가 궁금하면 data-airflow-dags를 clone. Claude가 로컬 파일을 직접 읽으니까 별도 연동 없이 바로 작업 가능.
관리 포인트가 적다.
외부 서비스 연동 없이 로컬 파일만 쓰니까, 서버가 죽거나 키가 만료되는 걱정이 없음. 뭔가 틀리면 .md 파일 열어서 고치면 끝.
보안이 단순하다.
데이터가 로컬에서 벗어나지 않으니까 보안 리뷰가 간단함. 금융 데이터를 다루는 팀에겐 이게 편함.
셋업이 5분이다.
git clone → Obsidian vault 열기 → 기준 문서 작성. 새 팀원이 와도 5분이면 같은 환경에서 시작.
도구를 더 쓰면 더 잘 될 수도 있겠지만, 지금은 마크다운 파일과 git만으로 저희한테 필요한 건 충분히 되고 있습니다.
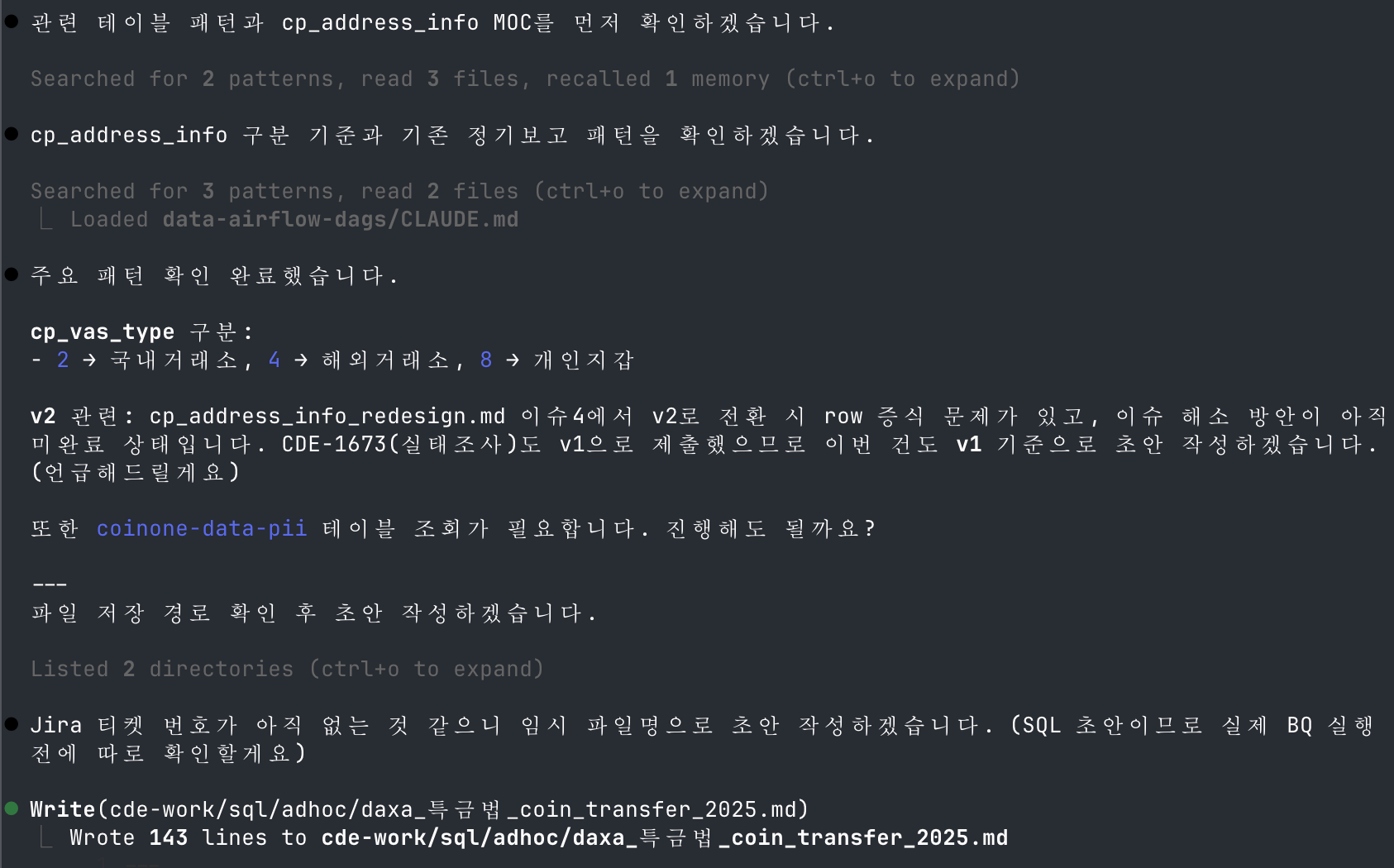
요청이 들어오면
금융 당국 및 외부 기관에 데이터를 제출하는 팀입니다. 기한은 짧고, 기관마다 기준이 다르고, 작업할 때 2~3년치 변경 이력까지 고려해야 합니다. 이 기준이 사람 머릿속에만 있어서, 파일에 쌓아두고 AI가 조합하는 방식을 택했습니다.
01
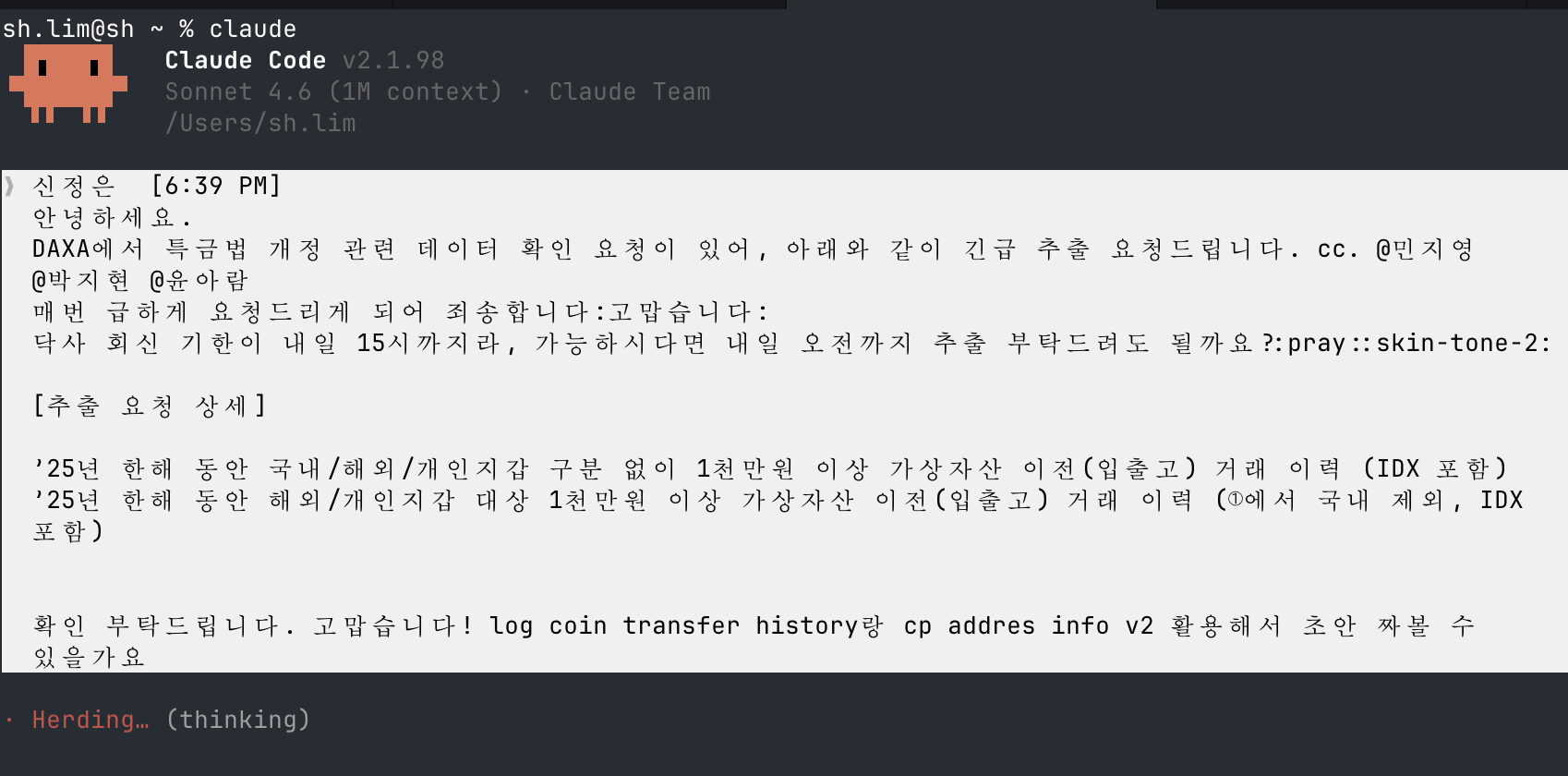
Slack 요청을 그대로 붙여넣기
DAXA 코인 이전 데이터 긴급 추출 요청. 요청서 텍스트를 Claude에 그대로 전달.
02
Claude가 관련 기준을 직접 찾아 읽음
· cp_address_info MOC에서 구조와 기존 패턴 확인
· Memory에서 v1/v2 차이, CDE-1673 선례 참조
· CLAUDE.md에서 SQL 규칙, 컬럼 명명 규칙 로드
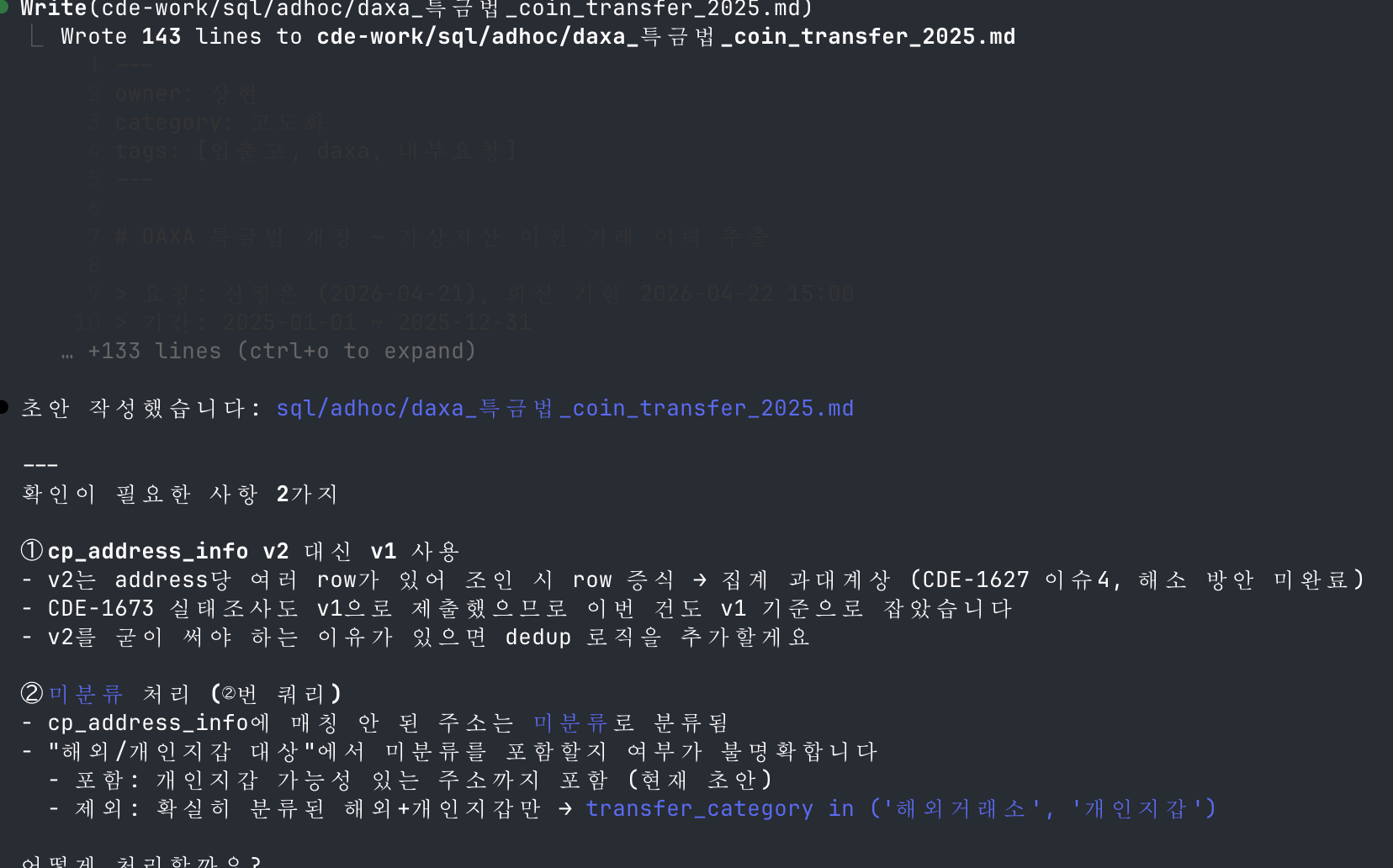
03
SQL 초안 작성 + 검증 포인트 제시
초안을 파일로 작성하고, 사람이 확인해야 할 것 2가지를 알아서 짚어줌. 초안 작성까지 수 분.
같은 방식으로 처리한 다른 건
AML 스테이블코인 테마모니터링 — 기한 4일
4개 소스 테이블을 조합하는 작업. 업무용 계정 제외, 단위 환산 같은 규칙을 Claude가 Memory와 CLAUDE.md에서 알아서 적용. 이 조합을 사람이 처음부터 파악하면 반나절인데, 초안은 바로 나왔고 검증 1회로 확정.
의원실 스테이블코인 보유·유출입 — 기한 1일
25년 3월 vs 26년 3월 보유량 비교. 함정: 두 시점에 써야 하는 소스 테이블이 다름. 모르고 같은 테이블로 추출하면 에러 없이 숫자가 조용히 틀림. Memory가 이 차이를 알고 있어서 자동 구분 적용.
여기에 쓰인 건 마크다운 파일과 텍스트 파일뿐입니다. RAG도, 프롬프트 엔지니어링도, 별도 프레임워크도 없음. 기준만 글로 남겨두면, 어떤 팀이든 바로 시작할 수 있습니다.
전과 후
수시 요청 처리 (월)
20.5건
26건
고도화 건수 (월)
4건
5.7건
정기보고 자동화 → 주 5시간 확보 → 수시 요청 + 고도화에 재투입.
기한 4일 요청을 2시간에 처리할 수 있었던 건 기준을 이미 알고 있었기 때문. 인원은 그대로인데, 일하는 방식이 완전히 달라졌습니다.
기준 자동 적용 — 시점별 테이블 차이, 필터 조건 변경 등을 Memory가 기억. 설명 없이 맞는 테이블, 맞는 필터가 적용됨.
반복 설명 제거 — "이건 금감원 기준이야, 금융위 기준이야?" 같은 확인이 필요 없어짐.
기록의 질 — 의사결정 근거, 기준 변경 이력, 실수 원인까지 문서에 남아있음.
62
기준 문서
30+
Memory 항목
11
MOC
따라하기
발표에서 본 것을 직접 해보고 싶다면. 순서대로 따라하면 됩니다.
Step 1. Obsidian 설치 + 폴더 열기
obsidian.md에서 다운로드 (무료). 설치 후 "Open folder as vault"로 아무 폴더나 열면 됩니다.
폴더 구조를 미리 잡으려 하지 마세요. 빈 폴더 하나면 충분합니다. 구조는 쓰면서 자연히 생깁니다.
Step 2. 기준 문서 하나 쓰기
"매번 AI에게 같은 말 반복하는 것"을 마크다운으로 적으면 됩니다. 처음엔 10줄이면 충분.
예를 들면:
# 우리 팀 규칙
## 코드 컨벤션 - 변수명은 snake_case - 커밋 메시지는 한국어로
## 자주 쓰는 테이블 - 유저 정보: user_account (PII 주의) - 거래 내역: trade_history (파티션: _PARTITIONTIME)
## 반복되는 실수 - prod 테이블 조회 전 반드시 확인 받기 - 금액 단위 환산 빠뜨리지 말 것
Claude Code를 쓴다면 → 파일명을 CLAUDE.md로 저장. 매 세션 시작할 때 자동으로 읽힘. Claude 웹을 쓴다면 → 프로젝트에 파일을 첨부하거나, 대화 시작할 때 내용을 붙여넣기.
Step 3. 평소처럼 일하기
AI에게 기준 문서를 읽게 하고 평소 하던 작업을 시키면 됩니다. 특별한 프롬프트가 필요하지 않습니다.
작업 중 "이건 다음에도 기억하면 좋겠다" 싶은 게 있으면 같은 폴더에 메모. Claude Code라면 작업 중에 알아서 Memory에 저장하기도 합니다.
Step 4. 작업 끝나면 "정리해줘" 한마디
작업이 끝나면 이렇게 말해보세요:
"이번 작업 배경이랑 기준 정리해서 md로 남겨줘"
AI가 작업 내용을 정리해서 마크다운 파일을 만들어줍니다. 이게 한 장씩 쌓이면서 팀의 기준 문서가 됩니다.
처음부터 문서 구조를 잡으려 하면 안 하게 됩니다. 일단 쌓고, 10개쯤 모이면 그때 정리해도 늦지 않습니다.